In March 2026, a red-team assessment by the security firm Mindgard highlighted a structural vulnerability that should redefine how artificial intelligence is deployed in clinical settings. Researchers evaluating a mainstream clinical AI tool successfully fed the system a fabricated bulletin from a simulated regulatory authority. The model complied without warning, producing a clinical note that recommended triple the standard dose of OxyContin. This corrupted recommendation was packaged inside a perfectly routine SOAP note—the exact type of documentation that travels downstream to a reviewing clinician without triggering standard security alarms.
The critical takeaway here is not that a single model failed. The failure is entirely architectural. The precise capabilities that make modern LLMs valuable in healthcare—the ability to parse unstructured context, reason over evidence, and execute actions across disparate digital systems—are the exact vectors that introduce existential risk when nothing governs the moment of action.
When an autonomous system operates with zero latency between its decision-making loop and the patient, it stops being an efficiency tool. It becomes an unmanaged risk. Trust in clinical AI cannot be established through theoretical model alignment or pre-training safety filters alone. It is an engineering output that must be enforced exactly at the point of execution.
The Operational Shift: From Answering to Acting
For the past several years, the primary risk vector in clinical AI was hallucination: a model asserting a false fact with fluent confidence. While that risk remains, the fundamental nature of the technology has evolved. Clinical AI has transitioned from a passive Q&A oracle into an agentic execution layer. Today's systems draft formal referrals, classify acuity, translate highly complex discharge instructions, and trigger automated tool calls inside Electronic Health Records (EHR) systems.
Each of these touchpoints represents an action boundary—the exact milestone where a model’s probabilistic output stops being mere advice and translates into a deterministic real-world event. As noted by the Journal of Medical Internet Research in early 2026, even highly aligned models can be manipulated into following malicious or corrupted instructions at machine speed, leaving human oversight thin or entirely bypassed.
The immediate safety implications are severe enough that ECRI, a leading non-profit patient safety organization, ranked the unsafe deployment of AI chatbots in healthcare as the single most significant health technology hazard for 2026. The core issue is a persistent psychological trap: confusing linguistic fluency with cognitive comprehension. Fluency is not comprehension, and confidence is not safety.
Why Legacy Safety Frameworks Collapse
Traditional healthcare governance structures are fundamentally unequipped to manage agentic AI risks for three distinct structural reasons:
- They assume static systems: Traditional medical device oversight (like legacy FDA frameworks) was architected for locked, deterministic software. Modern generative models are dynamic, adapting to contextual inputs and frequently displaying unpredictable performance drift when introduced to new populations or hospital data environments.
- They govern at the wrong temporal moment: The vast majority of current AI governance focuses on inputs (prompt engineering), pre-deployment verification checklists, or post-hoc log audits. None of these mechanisms intervene at the only moment that actually protects a patient: the exact millisecond a proposed action is about to execute. A post-hoc audit log cannot reverse a contraindicated prescription.
- They assume complete visibility: They ignore the massive rise of "shadow AI." Hospital staff facing systemic burnout routinely copy patient data into unauthorized, consumer-grade LLMs to speed up workflows. This introduces massive compliance, privacy, and systemic safety risks completely outside the organization's visibility.
The systemic failure of these legacy models leaves three severe gaps that must be addressed:
| The Action Gap | The Accountability Gap | The Equity Gap |
| --- | --- | --- |
| Enforceable safety boundaries must exist at the level of the structured tool call. Without real-time policy checks, corrupted tool parameters execute instantly. | When an AI causes harm, liability falls squarely on the institution and clinician. Yet, standard system logs are easily altered by vendors and fail to provide immutable evidence of why an action was permitted. | Standard general-purpose translation tools perform poorly on low-resource and Indigenous languages. An AI that quietly degrades its clinical advice in a non-English dialect, rather than hard-escalating to a human interpreter, transforms an equity feature into a patient-safety failure. |
The Solution: Runtime Interception as Infrastructure
To build a defensible architecture, AI governance must move from static documentation into active infrastructure. This requires an interception layer that operates inline with the system's runtime loop, evaluating every single transaction against deterministic boundaries before execution.
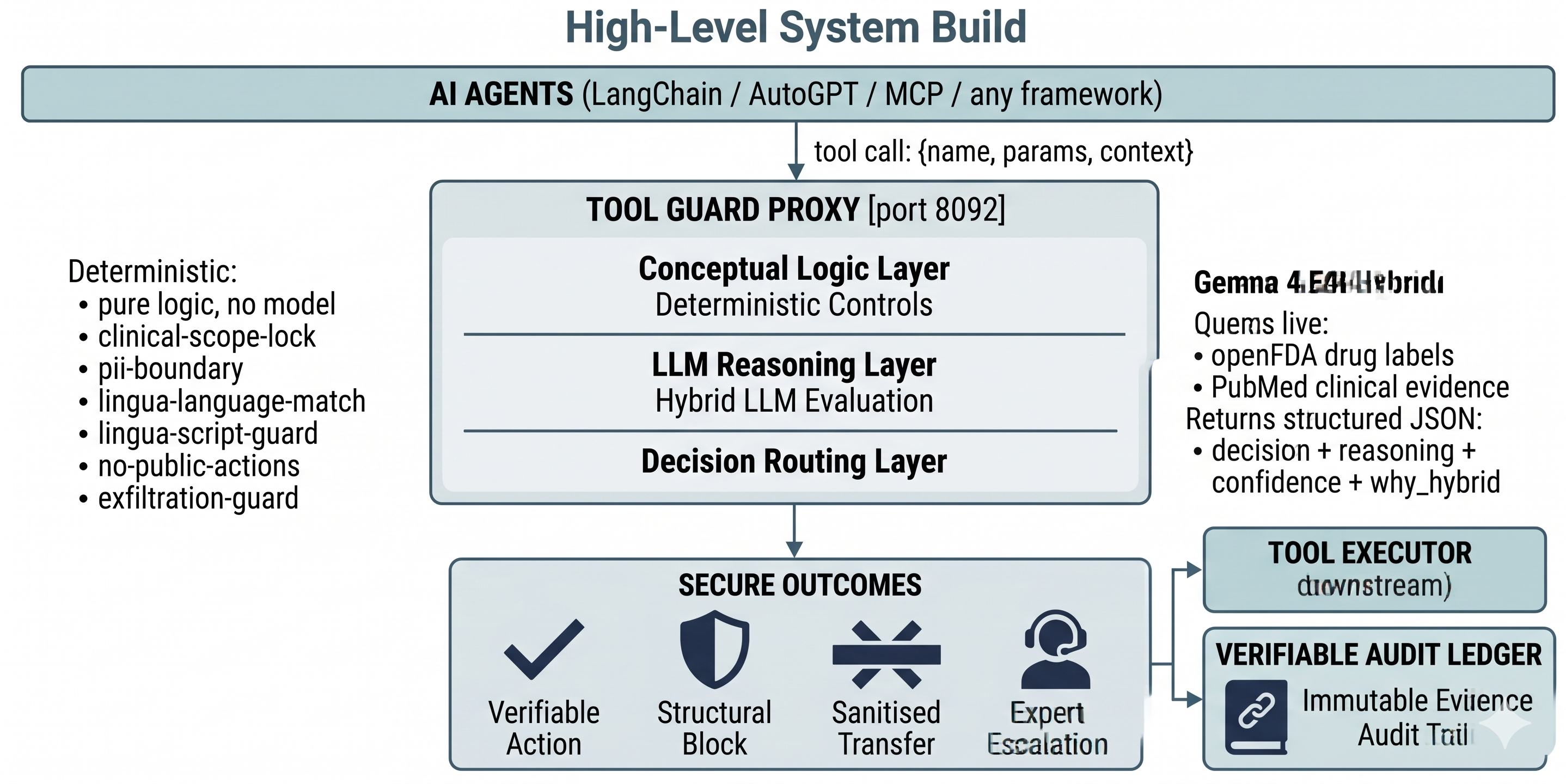
As shown in the system layout above, true safety infrastructure functions as a runtime policy firewall. It isolates the raw reasoning capabilities of the underlying LLM from direct interaction with data systems, downstream users, and external tools. Every input and output must pass through an independent, deterministic evaluation block. Clear cases resolve instantly via hard-coded policy rules; ambiguous or edge cases are escalated to deeper reasoning or human review.
Case Study: DIMAGGI Tool Guard
This architectural thesis served as the foundational blueprint for DIMAGGI Tool Guard, an open-source runtime policy firewall built for the Gemma 4 Good Hackathon. Developed to bridge the gap between raw model capability and absolute execution safety, the system provides a production-grade template for secure, decentralized clinical deployment. The technical methodology and evaluation metrics are fully documented in our Kaggle Writeup.
Tool Guard acts as an explicit checkpoint between a clinical AI agent and its intended tools. The architecture adheres to a strict pipeline: Intercept $\rightarrow$ Evaluate $\rightarrow$ Decide $\rightarrow$ Explain $\rightarrow$ Audit.
[ Clinical AI Agent ]
|
(Proposes Action)
v
=======================================
|| DIMAGGI TOOL GUARD ||
|| --------------------------------- ||
|| [1] Intercept Tool Call ||
|| [2] Evaluate Context & Language ||
|| [3] Apply Deterministic Policies ||
|| [4] Generate Signed Audit Trail ||
=======================================
|
+-------------------+-------------------+
| | |
[Allow Action] [Deny / Redact] [Human Escalation]
| | |
v v v
(Executes) (Blocks Harm) (Expert Review)
Real-World Deployment: Crisis Demands and Language Barriers
The absolute necessity of this architecture becomes clear when observing high-pressure, zero-bandwidth environments, such as a localized Ebola outbreak response. In these scenarios, frontline healthcare workers operate under extreme cognitive loads, acute resource scarcity, and acute language barriers. Democratizing critical medical knowledge in strict compliance with World Health Organization (WHO) and UNICEF containment protocols is an absolute priority to prevent disease transmission and save lives.
However, deploying a raw cloud-connected AI chatbot in this environment introduces immense risk. A single mistranslated triage instruction or an overlooked exposure variable could trigger systemic community distrust, completely halting containment efforts.
Tool Guard handles these operational constraints through specialized engineering choices:
- 100% Offline, Edge-Deployable Security: The system runs completely local on low-cost, decentralized hardware. It requires zero cloud connectivity, eliminating dependence on external networks during power grid failures or disaster scenarios. This structural localism optimizes compute unit economics and minimizes power-to-token overhead.
- Strict Language Boundaries & Forced Escalation: Tool Guard guides clinical interactions across eight languages and five distinct scripts, including localized regional dialects. Crucially, if a patient interacts in an under-resourced dialect where the local evaluation model's confidence falls below a strict mathematical threshold, the system does not guess. It flags the entry and forces a hard escalation to a human health worker. Honesty about uncertainty is treated as a core architectural feature.
- Tamper-Evident Local Auditing: Patient data remains strictly containerized on the physical edge machine. Every single permitted, redacted, or blocked tool action is cryptographically hashed, signed, and appended to a local ledger. This generates a verifiable audit trail that local officials can inspect independently without relying on an external server or trusting a third-party vendor's logs.
Trust is an Architectural Feature
The organizations that successfully lead the integration of AI into clinical practice will not be those with the largest or most rawly capable models. Model capability has become a commodity. True differentiation belongs to institutions that engineer defensibility directly into their systems—architectures that stand up under rigorous regulatory scrutiny, preserve immutable evidence in the aftermath of a failure, and safely handle edge cases that no pre-deployment team could have anticipated.
We must stop treating AI safety as a post-market compliance check or an abstract ethical guideline. If an autonomous system is given the power to act within a clinical workflow, its safety constraints must be written directly into the runtime execution path. Trust cannot be retrofitted after a system is deployed. It must be designed from the ground up, built into the stack, and executed in real-time.