AI agents are probabilistic. Enforcement has to be deterministic. That means moving the rule out of the model and into a gate the model does not get to argue with.
The same disappointment shows up for everyone who has tried to make an AI agent behave reliably. You write the rule. You put it in the system prompt, the memory file, the project instructions. You are specific and unambiguous. Then, deep into a long session, the agent skips the step anyway and walks it back with an apology when you catch it.
That failure is not a wording problem. It is a property of the technology. You cannot fix it with a better sentence, because the rule was never a constraint. It was an input to a probability distribution. The fix is to stop keeping the rule on that surface at all. You move it to a checkpoint outside the model, one that checks every tool call against your policy before it runs, returns one of four verdicts (allow, flag, escalate, or deny), and logs each decision so it cannot be quietly rewritten. A rule the model cannot reach is a rule that a long session, a jailbreak, or a bad day cannot erode. That checkpoint is DIMAGGI Tool Guard, and what follows is why instruction-based guardrails cannot hold and how the checkpoint is built.
An instruction is not a constraint
An instruction to a language model is not a rule it must obey. It is text the model weighs against everything else in its context.
Large language models were not built with a blueprint for logic, hard rules, or deterministic obedience. At the foundational layer they are probabilistic predictors trained to guess the next token. Everything they appear to follow is filtered through that mechanism.
Call the ability to follow directions what it is: accidental competence. That an agent can honor an instruction, write working code, or execute a multi-step task is an emergent byproduct of scale and compute, not a designed feature with guarantees behind it. It is the kind of safety that works until the one time it does not, and nothing in the architecture promises that the instruction wins.
This is the core paradox. Because behavior is governed by probabilities rather than hardcoded rules, more text cannot force adherence to a rule. "Never skip step X" and "always ask before deleting" are just more tokens to weigh. When the statistics point elsewhere, the rule loses, and it loses silently.
The problem compounds as the session runs. The more context the model consumes, the more its attention on any single instruction decays. A rule that held at token 500 is weaker at token 50,000, which is why long-running agents end up needing constant supervision to stay on their own stated rails.
The people closest to the problem have stopped arguing about wording
The practitioner consensus has shifted from how to phrase a rule to where to put a rule so the model cannot reinterpret it.
The teams building real agent workflows have thrown the full toolbox at this. Steering files. Instruction manifests. Hooks. Skills. Validation agents. Custom workflow engines built around the model for the sole purpose of keeping it on rails. Each helps at the margins. None of them makes an instruction binding.
The pattern in that collective experience is consistent. Instructions shape behavior. They do not bind it. Hooks can force a specific tool call at a specific boundary, but only where a clean boundary exists, which is not everywhere. And the moment you need scaffolding this elaborate to get reliability, you have conceded the original selling point: that you could simply tell the system what to do in plain language and trust the result.
So the useful question changed. Not how to word the rule better, but how to move the rule somewhere the model does not get a vote.
Move the decision out of the model
The only guardrail that holds is one the model does not get to reason about, which means separating the thing that proposes an action from the thing that decides whether it is allowed.
The fix is architectural, not textual. In access control this split has a name: a policy decision point, a checkpoint that sits outside the model and evaluates a request against rules, paired with a policy enforcement point that carries out the verdict. Applied to agents, the model becomes a proposer. It suggests the action it wants to take. An external engine decides. The boundary enforces.
The reason this works is the reason instructions do not. A deterministic engine returns the same answer for the same input, every time. There is no next-token lottery in the decision path. The rule is code and configuration, not a sentence the model can talk itself out of under load. The proposer does not get to be the enforcer.
What DIMAGGI Tool Guard is
DIMAGGI Tool Guard is a policy decision engine that sits outside the agent and returns a verdict on every proposed tool call, plus a tamper-evident record of why (a log you cannot quietly edit after the fact).
Before an agent runs a tool, Tool Guard evaluates the call it wants to make against declarative policies you author, and returns one of four decisions: allow, flag, escalate, or deny. The open-source Core is a policy decision point. It decides and records. Your execution layer, or the Enterprise gateway, enforces. That separation is deliberate and worth stating plainly: the judgment is removed from the model, so the model no longer gets to decide whether a rule applies to it.
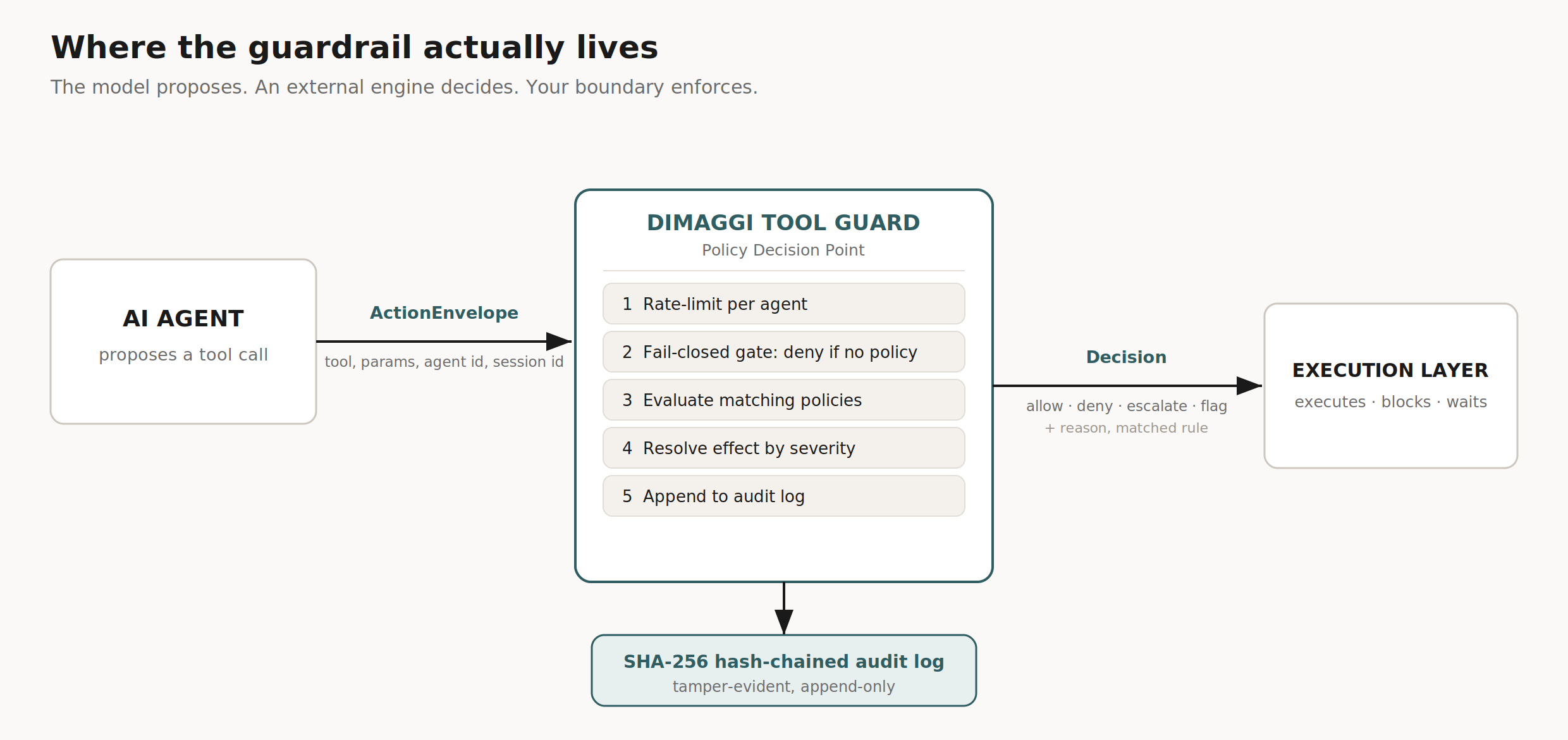
Figure 1. Tool Guard evaluates the agent's proposed call and returns a verdict; the execution layer carries it out. The decision does not depend on the model's reasoning.
Walk the flow. The agent builds a structured envelope describing the call it wants to make: which agent, which session, which tool, and the parameters. The engine rate-limits per agent, refuses to run when no policy is loaded (it fails closed on a missing policy), evaluates every policy that matches the tool, and resolves conflicts by severity. A deny outranks an escalate, which outranks a flag, which outranks an allow. It returns the verdict along with the rule that matched and the reason. Evaluation is pure computation with microsecond latency and no network calls in the decision path.
A policy is a rule you can read, not a prompt you hope holds
Policies are declarative YAML authored by operators, and every rule can cite the document that justifies it.
A policy names the tools it governs, sets conditions, and attaches an effect. Here is the canonical example, capping refunds:
policy_id: pol-refund-cap
name: refund-cap
description: Allow refunds under $500; deny above.
version: 1
status: approved
mode: enforcement
scope:
tool_names: [issue_refund]
tool_groups: [monetary_outflow]
rules:
- rule_id: rule-amount-cap
name: Single refund amount limit
rule_type: threshold
conditions:
field: amount
operator: gt
value: 500
effect: deny
effect_config:
severity: high
suggested_response: "Refunds over $500 require supervisor approval."
citation:
document_id: doc-refund-sop
section: "2.3"
excerpt: "Individual refund transactions exceeding $500 require supervisor approval prior to processing."Read what that buys you. The scope limits the rule to the refund tool. The condition is a plain comparison. The effect is a hard deny. And the citation points at the section of the standard operating procedure that mandates the limit, so the same rule is legible to a compliance reviewer and to an engineer at once. The rule is not a hope. It is a statement of policy with a decision attached.
Rules are not limited to numeric thresholds. Conditions compose with and, or, and not, and can call classifiers for SQL, filesystem paths, and shell commands, so "deny destructive SQL against production" or "block writes outside the working directory" are expressible, not just dollar limits.
The four effects define the entire decision surface.
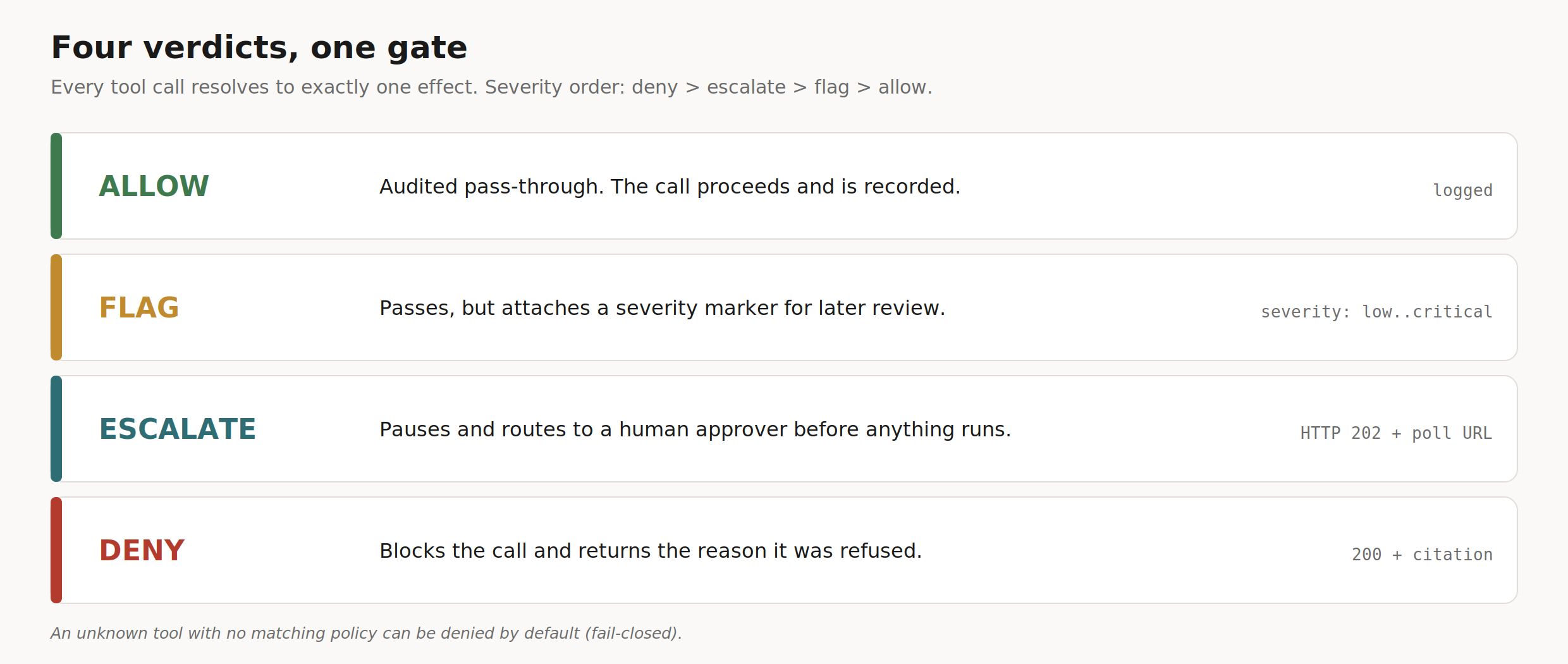
Figure 2. Every proposed call resolves to exactly one effect, and conflicts resolve by severity.
Escalate is where the human comes in. When a rule escalates, the call pauses, the agent receives a poll URL and waits, and a human approver decides. Approvals are authenticated and write their own record. In the open-source Core, that escalation is exposed through the API. The reviewer dashboard is an Enterprise feature.
Every decision leaves a receipt the agent cannot forge
Tool Guard writes an append-only, hash-chained audit log, so the record of what was decided and why is tamper-evident.
Each decision is written as a record whose hash covers the decision and the fields that produced it, then linked to the hash of the record before it, so each entry seals the one before it. Change any earlier record and the chain breaks at that point. Startup validation refuses to load a corrupted log, and an offline verifier confirms the chain is intact or reports exactly where it was altered.
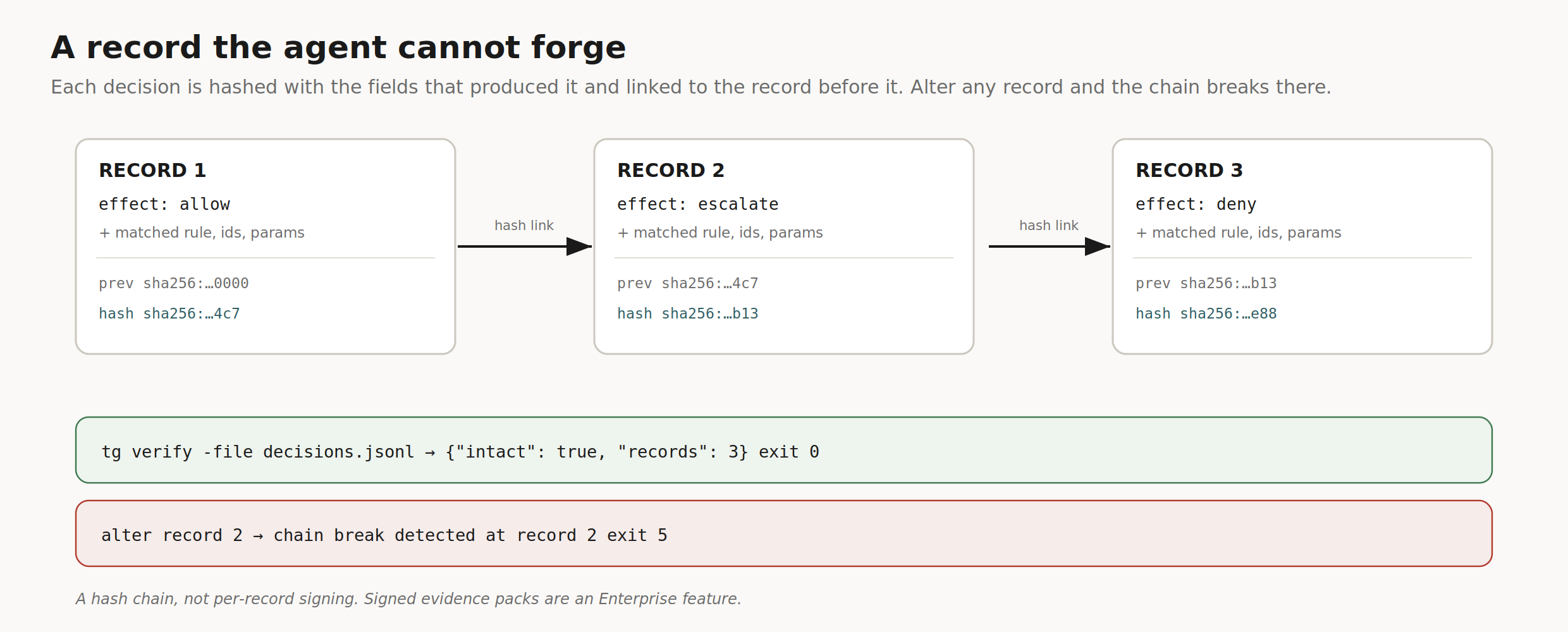
Figure 3. Records are chained by hash. Altering one breaks the link, and the verifier reports the break.
This closes the accountability gap that instruction-based agents leave wide open. The standard failure mode is that when an agent deviates, there is no reliable, tamper-proof record of what it did or why. A hash-chained log converts an unanswerable question, did the agent actually do what it claimed, into a checkable one, is there an unbroken record. To be precise about the mechanism: this is a hash chain, not per-record cryptographic signing. Signed evidence packs are an Enterprise feature.
How standard agents fail, and what an external gate changes
The difference between a prompt-based guardrail and an external gate is the difference between a rule the model can reinterpret and a rule the model gets no vote over.
| The standard failure mode | What an external gate changes |
| --- | --- |
| The rule lives in the prompt. Because behavior is probabilistic, the agent can reinterpret or quietly drop it. | The rule lives in an engine outside the model. The model does not get a vote on whether it applies. |
| The agent triggers actions directly, so a single lapse becomes an immediate action in the world. | Sensitive actions are evaluated before execution and can be denied, held for a human, or flagged. |
| A deviation leaves no reliable account of what happened or why. | Every decision is written to a tamper-evident, hash-chained log with the matched rule and the reason. |
What Tool Guard does not do
Tool Guard is a decision and enforcement layer, not a smarter model, and the open-source Core decides rather than blocks on its own.
Being precise about the boundaries is the whole point of the approach, so here they are. Core returns a verdict, and something in your stack has to honor it. If your execution layer never consults the engine, or ignores the answer, nothing is enforced. The single inline enforcement point, a full gateway that blocks at the boundary, is the Enterprise product. The open-source repository gives you the deterministic decision engine and the audit chain, not a drop-in blocker. Two boundaries deserve to be named plainly. The reference PreToolUse hook fails open on evaluator error, so a check that itself errors or times out lets the call through, which means fail-closed enforcement is the job of your execution layer or the Enterprise gateway. And the open-source policy and configuration files are not write-protected from the agent's own user, so treat the guard's own files as part of your threat model.
The engine also ships a semantic classifier that runs locally and fails closed on timeout or refusal, but the deterministic strength is in the field comparisons and the SQL, path, and shell classifiers, not in asking another model for its opinion. And the open-source surface is Go and REST. There are no Python or Node SDKs, no built-in PII redaction, and no signed evidence packs. Those live in Enterprise.
None of this is a hedge. A guardrail you can trust is one whose behavior does not depend on a model's mood. Tool Guard is deliberately boring exactly where boring is the feature.
The shape of production-grade autonomy
For most of computing history the defining trait of a machine was that it obeyed. Agents trade obedience for judgment, and judgment cannot be commanded by instruction, so you stop commanding it and start gating it.
A computer's oldest promise was that it did exactly what it was told. Agents break that promise on purpose. What makes them worth running, the judgment they bring to open-ended work, is the same property that makes them impossible to bind with a sentence. You do not fix that by writing the sentence louder. You put a gate around the judgment.
The model proposes. An external engine decides. The boundary enforces. Every action leaves a record the agent cannot forge. That is not a limitation to apologize for. It is what production-grade autonomy looks like once you stop pretending the model will police itself.
DIMAGGI Tool Guard is how we build that gate. See it in practice with DIMAGGI AI, or put deterministic enforcement in front of your own agents: Partner with us on DIMAGGI Tool Guard.
— The DIMAGGI AI Team